Kayıp Verileri Görmezden mi Gelmeliyiz Yoksa İşlemeli miyiz?
Eksik veri kümeleri makine öğrenimi modellerinin doğruluğunu tehlikeye atabilir.
İstatistiksel analizlerde eksik veri içeren veri kümeleriyle sıklıkla karşılaşılır. İdeal olarak, eksik veriler potansiyel önyargı veya bozulma nedeniyle yanlışlıklara yol açabileceğinden eksiksiz veri kümesiyle çalışmak istenir. Ayrıca, makine öğrenimi modellerinin çoğunda boş satırları veya sütunları otomatik olarak işleme olanağı bulunmadığından, eksik verilerin işlenmesi her zaman isteğe bağlı değildir. Eksik verilerin işlenmesi iki şekilde gerçekleştirilebilir: ilgili satırın/sütunun kaldırılması veya eksik değerin yüklenmesi. İlk yöntem, özellikle veri kümesi küçük olduğunda tercih edilmeyen veri kaybına yol açar. İkinci yöntem, eksik değerlerin çeşitli istatistiksel tekniklerle ikame edilmesidir ve bu yazının konusunu oluşturmaktadır.
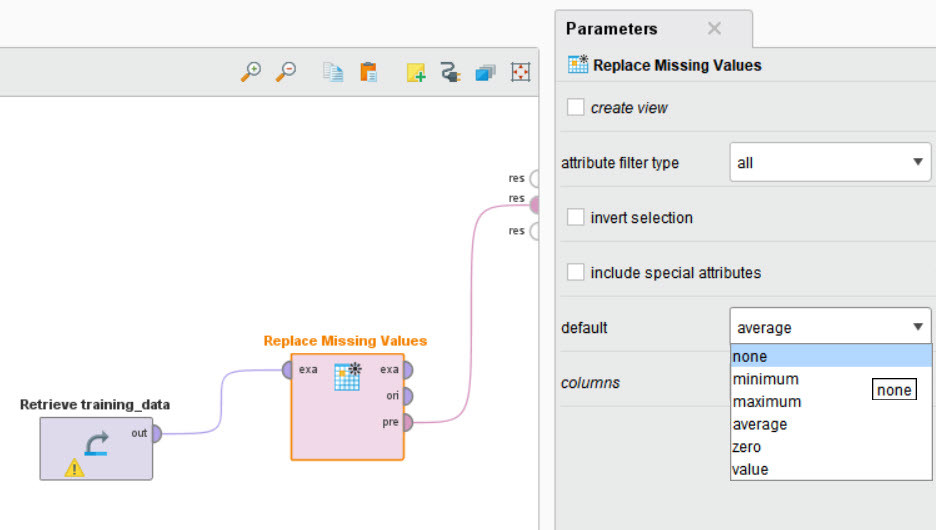
Veri doldurma, eksik verileri değiştirmek için kullanılan istatistiksel bir prosedürdür ve gerektiğinde makine öğrenimi modellerinin oluşturulmasında önemli bir adımdır. Veri doldurma birçok farklı teknikle gerçekleştirilebilir; bazıları min/maks/ortalama değerlerle değiştirmek kadar basit, bazıları ise regresyon tabanlı ikame gibi gelişmiş tekniklerdir. Veri doldurma sorunsuz değildir ve duruma bağlı olarak ters etki yaratabilir. Örneğin, veri doldurmanın yanlış uygulanması tahminlerinizi etkileyebilir.
Veri doldurma yöntemleri Python’un birçok genel kütüphanesinde mevcuttur. Bununla birlikte, Altair Veri Analitiği Araçlarından birini kullanıyorsanız, harici bir işleme gerek kalmadan veri manipülasyonunu yazılım içinde halletmek uygun olabilir. Altair HyperStudy, Altair Knowledge Studio ve Altair RapidMiner eksik verileri işlemek için kendilerine özgü yöntemler sunmaktadır.


Sorularınızı iletişim formunu kullanarak paylaşabilirsiniz.